The CRATE Language Model: Improved Neuron-level Interpretability
Re-proposing the CRATE Architecture in the Language Domain
We apply the
original CRATE architecture to the
next-token prediction task proposed in
GPT-2. This leads to several modifications in the model architecture:
1. We apply a
causal mask to ensure the model does not see tokens after the current one.
2. We
over-parameterize (increase the hidden dimension) of the
ISTA block to match GPT-2's MLP block.
These modifications result in the block architecture below:
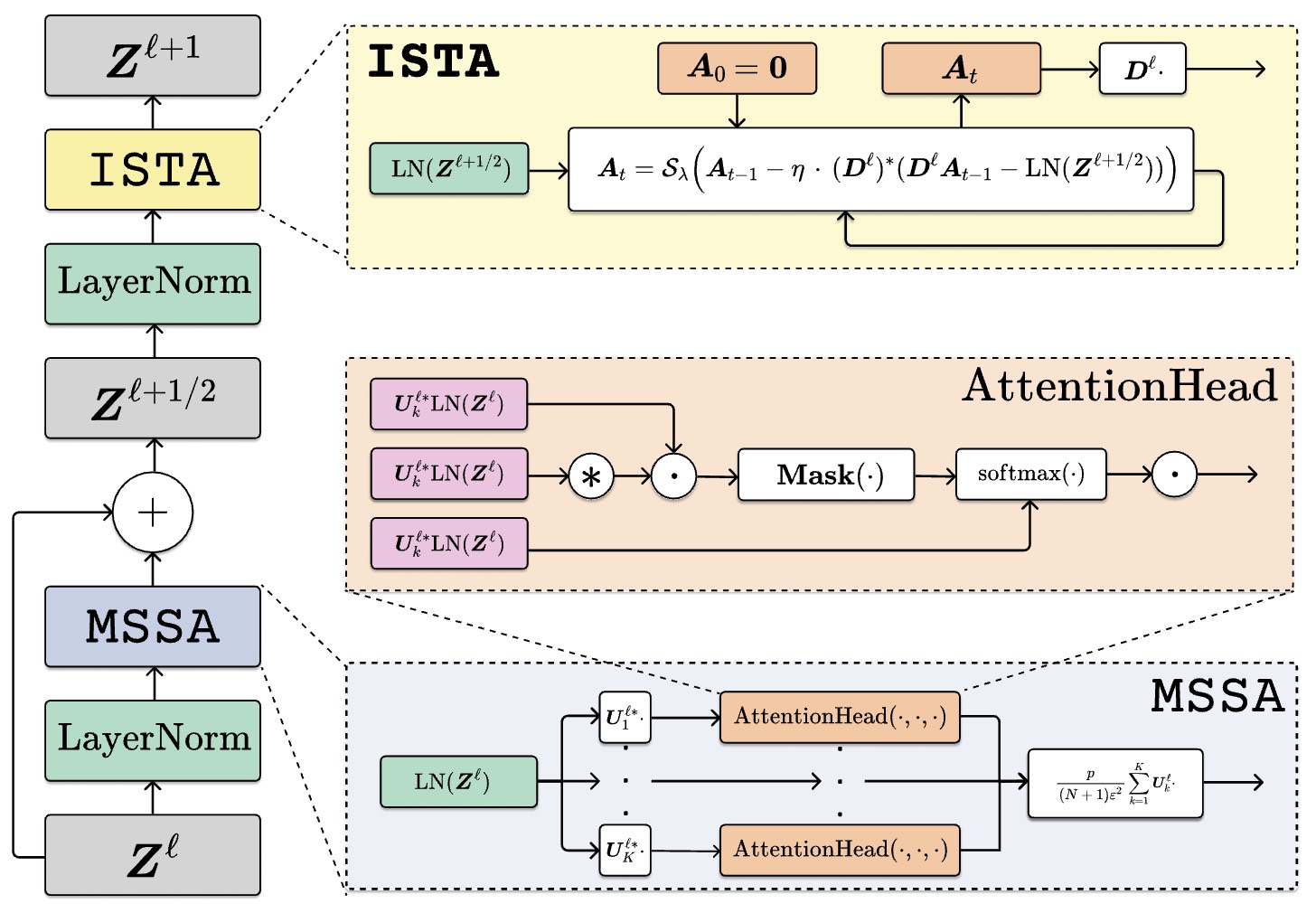
Block architecture for the CRATE language model.
Despite the change of the block architecture, the
embedding layer and heads are adjusted to accommodate the language vocabulary. Previously the embedding layer and head were the same as the
Visual Transformer. The resulting model configurations of the CRATE-LM and GPT-2 are shown below:
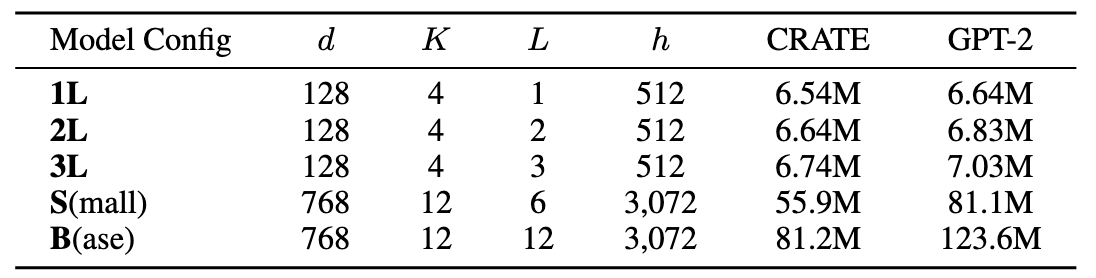
Model configuration of CRATE and model size comparison to GPT-2.
How Does the CRATE Language Model Process Tokens?
The process starts with random token representations. Through successive layers, the representations are
compressed to align with the axis via the MSSA block, forming intermediate representations are semantically more consistent among relevant tokens. This is then refined by
sparse coding (the ISTA block) to produce the final representations that align on incoherent axes, leading to semantically more specified token representations. Repeated across layers, this culminates in distinct token representations aligned on unique semantic axes.
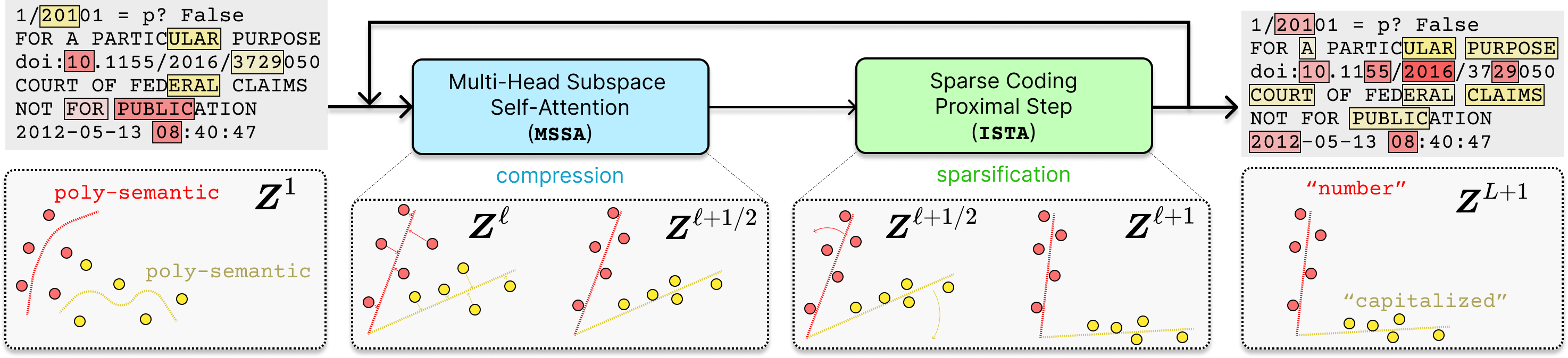
CRATE iteratively compresses (MSSA block) and sparsifies (ISTA block) the token representations (colored points) across its layers from 1 to L, transforming them into parsimonious representations aligned on axes (colored lines) with distinct semantic meanings.
Performance on the Next Token Prediction Task
We pre-train CRATE-Base and GPT2-Base on
the Pile dataset (uncopyrighted). The training recipe is similar to
GPT-2, please check our paper for details!
Key takeaways of performance experiments:
1. Both training and validation loss curve of CRATE-Base on the Pile dataset converges well.
2. The performance of CRATE is close to GPT-2 across all model sizes.
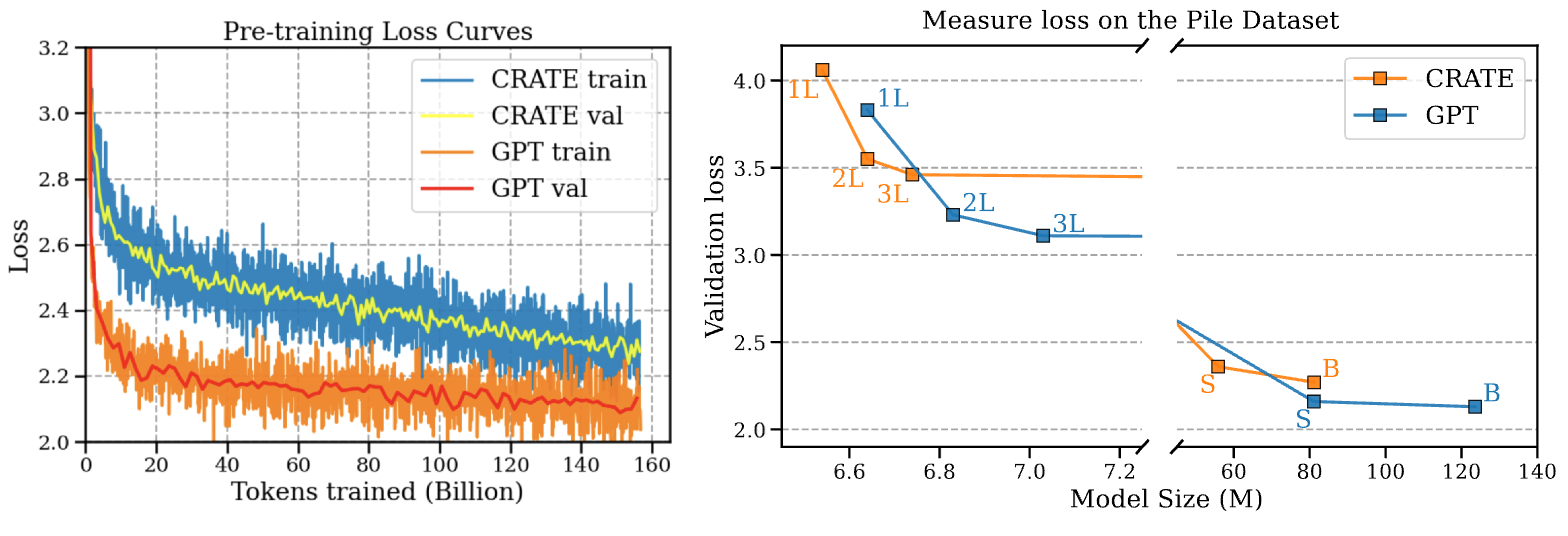
Left: loss curve when pre-training CRATE-Base and GPT2-Base on the Pile dataset.
Right: Validation loss of CRATE compared to GPT-2 on the Pile dataset, with respect to the model size.
3. CRATE-LM produces reasonable predictions.

Qualitative examples of predictions made by CRATE and GPT-2. The tokens in blue are considered good. We compare CRATE-Base to GPT2-Base on the next word prediction task.
Doubling Neuron-level Interpretability
CRATE achieves markedly improved and more steady neuron-level interpretability across layers compared to GPT-2, applicable across a wide range of model sizes.
1. CRATE comprehensively outperforms GPT-2 on all metrics for L∈{2,3,6,12}. When averaging the mean interpretability across all metrics, CRATE outperforms GPT-2 up to strikingly 103% relative improvement under the OpenAI Random-only metric when L=6.
2. The interpretability of CRATE is much more steady than GPT-2 across all model sizes.

Mean and variance of the average interpretability across layers for different model sizes.
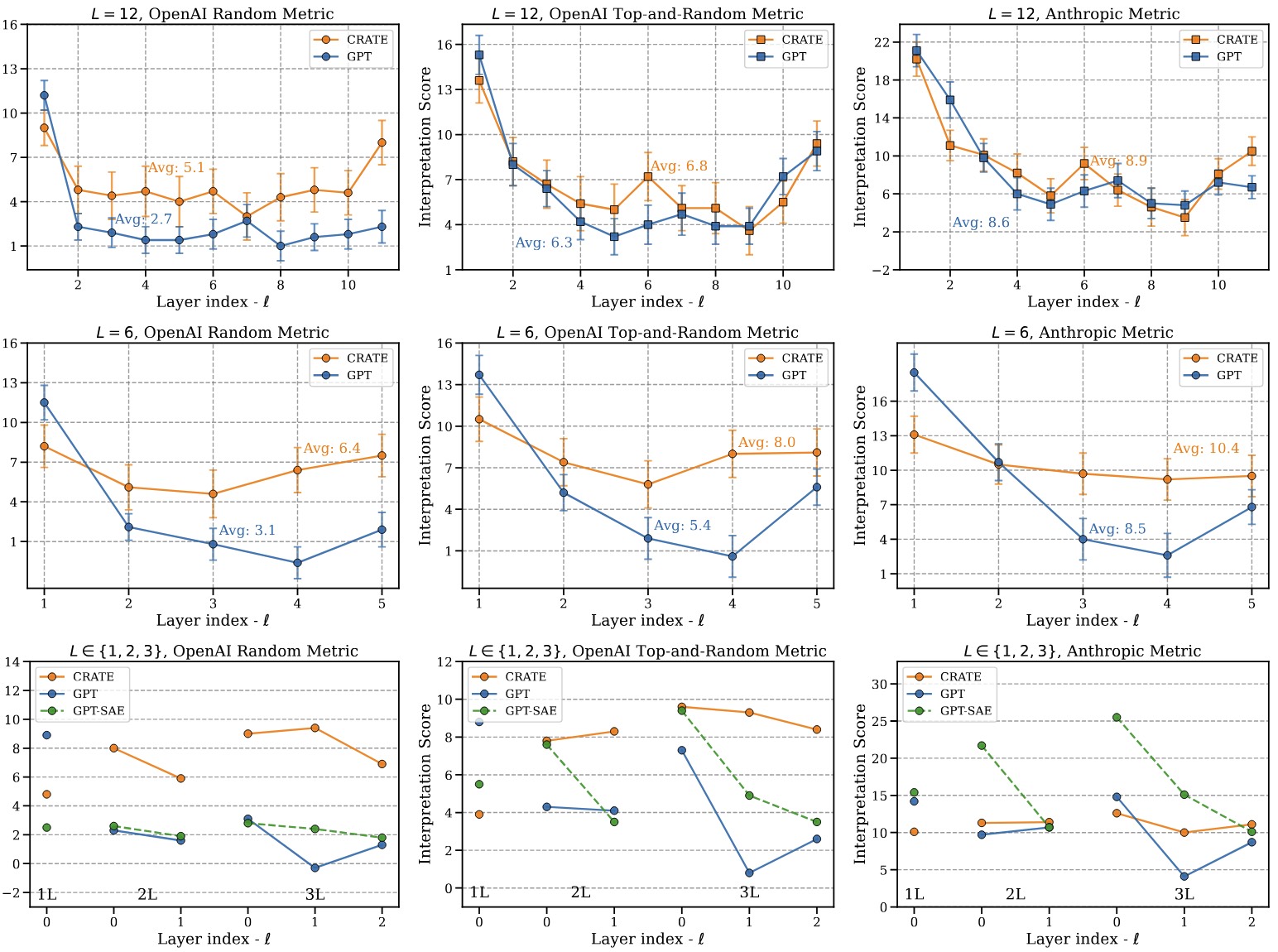
Layer-wise interpretation scores evaluated using the OpenAI Random-only metric, Top-and-Random metric, and Anthropic metric, respectively.
Top: interpretation scores of CRATE and GPT-2 for L=12.
Middle: interpretation scores of CRATE and GPT-2 for L=6.
Bottom: interpretation scores of CRATE, GPT-2, and GPT-2 with sparse auto-encoder for L∈{1,2,3}.
Variance bars are normalized to 1/10 of its original size.
Where Does the Improved Neuron-level Interpretability of CRATE Come From?
The strong interpretability of CRATE on the OpenAI Top-and-Random metric and the Anthropic metric, as shown in the averaged interpretability table above, indicates its consistent behavior on relevant tokens. These two methods contain a large portion of top-activated text excerpts, so they are valid for measuring whether the activations are consistent with the summarized explanation.
Additionally, the larger interpretability gap of CRATE and GPT-2 on the OpenAI Random-only metric versus the Top-and-Random metric highlights the specificity of CRATE in avoiding firing on irrelevant tokens. The random-only metric usually includes highly irrelevant text excerpts, so it effectively measures the capability of the language model to avoid activating on semantically irrelevant tokens.
Qualitatively, we show the interpretation examples in the figure below. In this figure, we list three neurons from CRATE (row 1) and GPT-2 (row 2), respectively. For each neuron, we show two top-activated text excerpts and one random excerpt.
Results show that CRATE is able to consistently activate on sementically similar tokens within the most relevant text excerpts, and does not activate on random tokens that are semantically distinguished from the top tokens. This promotes a more precise explanation given by the explanation model (e.g., Mistral).
On the other hand, GPT-2 is much worse at distinguishing tokens from different contexts, because it also has high activations on random text excerpts where the semantic meanings deviate far from the top activations.
How Does Interpretability of CRATE compare to GPT-2 with Sparse Auto-Encoder?
The interpretability scores of GPT2-SAE compared to CRATE and GPT-2, as depicted in the
layer-wise interpretability figure above (bottom row), reveal that under the long-context OpenAI metrics, GPT2-SAE matches GPT-2 but falls short of CRATE. This is attributed to its neuron activations becoming nearly 99% sparse after sparse auto-encoding, diminishing interpretability in long contexts. Conversely, under the Anthropic metric, GPT2-SAE surpasses both GPT-2 and CRATE in interpretability, corroborating findings in
Bricken et al. that post-hoc approaches enhance short-context interpretability, often a sign of mono-semanticity. However, the interpretability of GPT2-SAE on the Anthropic metric decreases significantly for layers that are deeper, while CRATE's remains steady, introducing concern in scalability of GPT-SAE.
Can We Steer the Next Token Predicted By Activating Neurons in CRATE?
We manually activate some neurons and observe the logit effects (changes of the token probability of the language model head). Compared to the lossy steering of the SAE models, CRATE can be steered without loss.


